Spark Streaming遇到问题分析
1、Spark2.0之后搞了个Structured Streaming
还没仔细了解,可参考:
2、Spark的Job与Streaming的Job有区别及Streaming Job并发控制:
先看看Spark Streaming 的 JobSet, Job,与 Spark Core 的 Job, Stage, TaskSet, Task 这几个概念。
[Spark Streaming]
- JobSet 的全限定名是:org.apache.spark.streaming.scheduler.JobSet
- Job 的全限定名是:org.apache.spark.streaming.scheduler.Job
[Spark Core]
- Job 没有一个对应的实体类,主要是通过 jobId:Int 来表示一个具体的 job
- Stage 的全限定名是:org.apache.spark.scheduler.Stage
- TaskSet 的全限定名是:org.apache.spark.scheduler.TaskSet
- Task 的全限定名是:org.apache.spark.scheduler.TaskSpark Core 的 Job, Stage, Task 就是我们“日常”谈论 Spark任务时所说的那些含义,而且在 Spark 的 WebUI 上有非常好的体现,比如下图就是 1 个 Job 包含duo1 个 Stage;3 个 Stage 各包含 8, 2, 4 个 Task。而 TaskSet 则是 Spark Core 的内部代码里用的类,是 Task 的集合,和 Stage 是同义的。

Spark Core中:一个RDD DAG Graph可以生成一个或多个Job。一个Job可以认为就是会最终输出一个结果RDD的一条由RDD组织而成的计算。Job在spark里应用里是一个被调度的单位。
Streaming中:一个batch的数据对应一个DStreamGraph,而一个DStreamGraph包含一或多个关于DStream的输出操作,每一个输出对应于一个Job,一个DStreamGraph对应一个JobSet,里面包含一个或多个Job。用下图表示如下:
生产的JobSet会提交给JobScheduler去执行,JobScheduler包含了一个线程池,通过spark.streaming.concurrentJobs参数来控制其大小,也就是可以并发执行的job数,默认是1.不过这个参数的设置以集群中executor机器的cpu core为准,比如集群中有2台4核executor,那么spark.streaming.concurrentJobs可以设置为2x4=8. 同时你还可以控制调度策略:spark.scheduler.mode (FIFO/FAIR) 默认是FIFO
我们的问题就是,运行一段时间之后发现处理速度跟不上了,后来才发现原来这个参数默认是1,而我们代码中对于每个batch有两个输出操作,这样会产生两个job,而同一时间只能执行一个job,慢慢地处理速度就跟不上生产速度了。所以实际中,请根据具体情况调整该参数。
此处参考:
3、 Spark Streaming缓存数据清理:
调用cache有两种情况,一种是调用DStream.cache,第二种是RDD.cache。事实上他们是完全一样的。
DStream的cache 动作只是将DStream的变量storageLevel 设置为MEMORY_ONLY_SER,然后在产生(或者获取)RDD的时候,调用RDD的persit方法进行设置。所以DStream.cache 产生的效果等价于RDD.cache(也就是你自己调用foreachRDD 将RDD 都设置一遍)
注意,当你调用dstream.cache缓存数据的时候,Streaming在该batch处理完毕后,默认会立即清除这个缓存,通过参数spark.streaming.unpersist 你是可以决定是否手工控制是否需要对cache住的数据进行清理.
参考:
4、Streaming中维持状态
有两种方式:updateStateByKey和mapWithState(Spark 1.6以后新增的)。
推荐使用mapWithState, 实际使用中,我发现updateStateByKey会慢慢拖慢处理速度,问题描述与该情况类似:许多复杂流处理流水线程序必须将状态保持一段时间,例如,如果你想实时了解网站用户行为,你需要将网站上各“用户会话(user session)”信息保存为持久状态并根据用户的行为对这一状态进行持续更新。这种有状态的流计算可以在Spark Streaming中使用updateStateByKey 方法实现。
在Spark 1.6 中,我们通过使用新API mapWithState极大地增强对状态流处理的支持。该新的API提供了通用模式的内置支持,而在以前使用updateStateByKey 方法来实现这一相同功能(如会话超时)需要进行手动编码和优化。因此,mapWithState 方法较之于updateStateByKey方法,有十倍之多的性能提升。
使用mapWithState方法进行状态流处理
尽管现有DStream中updateStateByKey方法能够允许用户执行状态计算,但使用mapWithState方法能够让用户更容易地表达程序逻辑,同时让性能提升10倍之多。让我们通过一个例子对mapWithState方法的优势进行阐述。假设我们要根据用户历史动作对某一网站的用户行为进行实时分析,对各个用户,我们需要保持用户动作的历史信息,然后根据这些历史信息得到用户的行为模型并输出到下游的数据存储当中。
在Spark Streaming中构建此应用程序时,我们首先需要获取用户动作流作为输入(例如通过Kafka或Kinesis),然后使用mapWithState 方法对输入进行转换操作以生成用户模型流,最后将处理后的数据流保存到数据存储当中。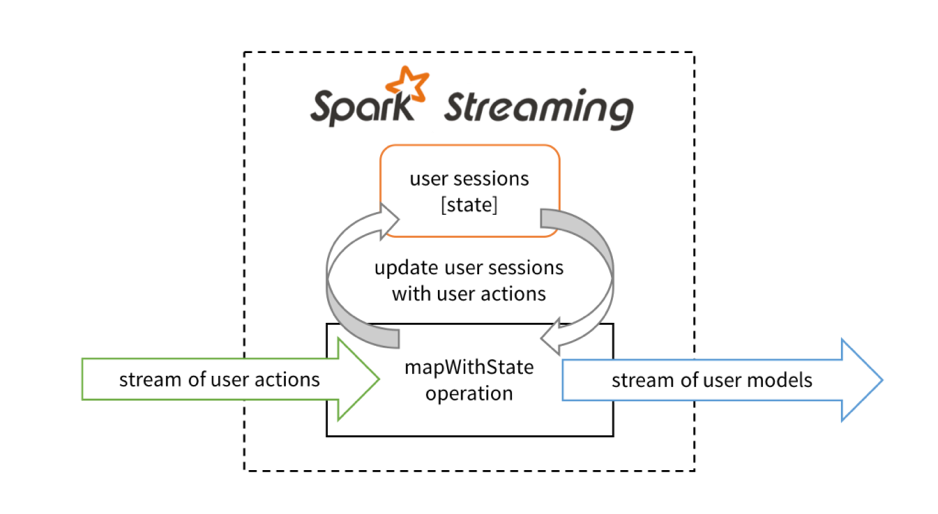
mapWithState方法可以通过下面的抽象方式进行理解,假设它是将用户动作和当前用户会话作为输入的一个算子(operator),基于某个输入动作,该算子能够有选择地更新用户会话,然后输出更新后的用户模型作为下游操作的输入。开发人员在定义mapWithState方法时可以指定该更新函数。
首先我们定义状态数据结构及状态更新函数:
def stateUpdateFunction(userId: UserId,newData: UserAction, stateData: State[UserSession]): UserModel = { val currentSession = stateData.get()// 获取当前会话数据 val updatedSession = ... // 使用newData计算更新后的会话 stateData.update(updatedSession) // 更新会话数据 val userModel = ... // 使用updatedSession计算模型 return userModel // 将模型发送给下游操作}// 用去动作构成的Stream,用户ID作为keyval userActions = ... // key-value元组(UserId, UserAction)构成的stream// 待提交的数据流val userModels = userActions.mapWithState(StateSpec.function(stateUpdateFunction))//--------------------------------------------------------------------------------------//java的例子Function3 , State , Void> mappingFunction =new Function3 , State , Void>() { @Override public Void call(String key,Optional value, State state) { // Use state.exists(), state.get(), state.update() and state.remove() // to manage state, and return the necessary string LiveInfo info=value.orNull(); if(info!=null){ state.update(info.getChannel()+":::"+info.getTime()); } return null; }};//处理计数samples//先将ip作为key.mapPartitionsToPair((v)->{ List > list=new ArrayList<>(); while(v.hasNext()){ Tuple2 tmpv = v.next(); String channelName=tmpv._1(); String ip=tmpv._2().getIp(); list.add(new Tuple2 (ip,tmpv._2())); } return list.iterator();})//更新状态.mapWithState( StateSpec.function(mappingFunction) //4小时没有更新则剔除 .timeout(Durations.minutes(4*60)))//获得状态快照流.stateSnapshots()//后续操作 mapWithState的新特性和性能改进
- 原生支持会话超时 许多基于会话的应用程序要求具备超时机制,当某个会话在一定的时间内(如用户没有显式地注销而结束会话)没有接收到新数据时就应该将其关闭,与使用updateStateByKey方法时需要手动进行编码实现所不同的是,开发人员可以通过mapWithState方法直接指定其超时时间。
userActions.mapWithState(StateSpec.function(stateUpdateFunction).timeout(Minutes(10)))
除超时机制外,开发人员也可以设置程序启动时的分区模式和初始状态信息。
- 任意数据都能够发送到下游 与updateStateByKey方法不同,任意数据都可以通过状态更新函数将数据发送到下游操作,这一点已经在前面的例子中有说明(例如通过用户会话状态返回用户模型),此外,最新状态的快照也能够被访问。
val userSessionSnapshots = userActions.mapWithState(statSpec).snapshotStream()
变量userSessionSnapshots 为一个DStream,其中各个RDD为各批(batch)数据处理后状态更新会话的快照,该DStream与updateStateByKey方法返回的DStream是等同的。
- 更高的性能 最后,与updateStateByKey方法相比,使用mapWithState方法能够得到6倍的低延迟同时维护的key状态数量要多10倍。
此部分参考:
5、如何理解时间窗口?时间窗口中数据是否会存在重复?

是否会存在重复?看下面两张图:


答案是:取决于你怎么设置窗口的两个参数
- (窗口长度)window length – 窗口覆盖的时间长度
- (滑动距离)sliding interval – 窗口启动的时间间隔
更深入请参考:
6、WAL(Write Ahead Log,预写日志)与容错机制
WAL是在 1.2 版本中就添加的特性。作用就是,将数据通过日志的方式写到可靠的存储,比如 HDFS、s3,在 driver 或 worker failure 时可以从在可靠存储上的日志文件恢复数据。WAL 在 driver 端和 executor 端都有应用。
WAL使用在文件系统和数据库用于数据操作的持久性,先把数据写到一个持久化的日志中,然后对数据做操作,如果操作过程中系统挂了,恢复的时候可以重新读取日志文件再次进行操作。 对于像kafka和flume这些使用接收器来接收数据的数据源。接收器作为一个长时间的任务运行在executor中,负责从数据源接收数据,如果数据源支持的话,向数据源确认接收到数据,然后把数据存储在executor的内存中,然后driver在exector上运行任务处理这些数据。如果wal启用了,所有接收到的数据会保存到一个日志文件中去(HDFS), 这样保存接收数据的持久性,此外,只有在数据写入到log中之后接收器才向数据源确认,这样drive重启后那些保存在内存中但是没有写入到log中的数据将会重新发送,这两点保证的数据的无丢失。启用WAL:
- 给streamingContext设置checkpoint的目录,该目录必须是HADOOP支持的文件系统,用来保存WAL和做Streaming的checkpoint
- spark.streaming.receiver.writeAheadLog.enable 设置为true
正常流程图:
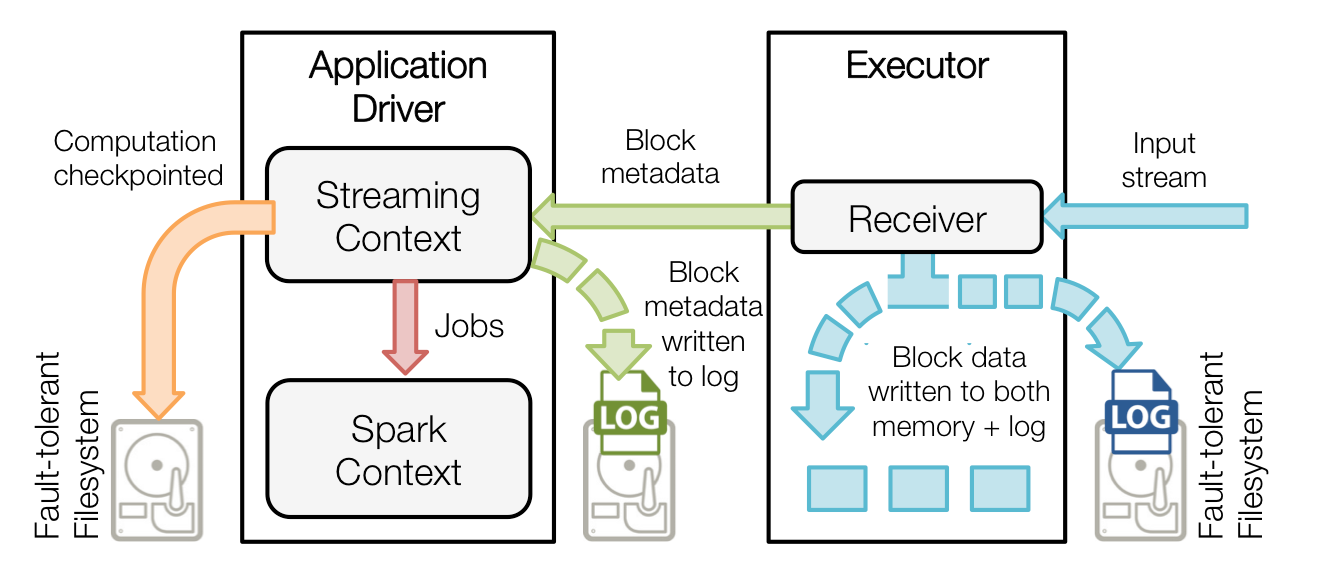 解析
解析 - 1:蓝色的箭头表示接收的数据,接收器把数据流打包成块,存储在executor的内存中,如果开启了WAL,将会把数据写入到存在容错文件系统的日志文件中
- 2:青色的箭头表示提醒driver, 接收到的数据块的元信息发送给driver中的StreamingContext, 这些元数据包括:executor内存中数据块的引用ID和日志文件中数据块的偏移信息
- 3:红色箭头表示处理数据,每一个批处理间隔,StreamingContext使用块信息用来生成RDD和jobs. SparkContext执行这些job用于处理executor内存中的数据块
- 4:黄色箭头表示checkpoint这些计算,以便于恢复。流式处理会周期的被checkpoint到文件中
当一个失败的driver重启以后,恢复流程如下:

- 1:黄色的箭头用于恢复计算,checkpointed的信息是用于重启driver,重新构造上下文和重启所有的receiver
- 2: 青色箭头恢复块元数据信息,所有的块信息对已恢复计算很重要
- 3:重新生成未完成的job(红色箭头),会使用到2恢复的元数据信息
- 4:读取保存在日志中的块(蓝色箭头),当job重新执行的时候,块数据将会直接从日志中读取,
- 5:重发没有确认的数据(紫色的箭头)。缓冲的数据没有写到WAL中去将会被重新发送。
1、WAL在 driver 端的应用
用于写日志的对象 writeAheadLogOption: WriteAheadLog在 StreamingContext 中的 JobScheduler 中的 ReceiverTracker 的 ReceivedBlockTracker 构造函数中被创建,ReceivedBlockTracker 用于管理已接收到的 blocks 信息。需要注意的是,这里只需要启用 checkpoint 就可以创建该 driver 端的 WAL 管理实例,将spark.streaming.receiver.writeAheadLog.enable 设置为 true。 首选需要明确的是,ReceivedBlockTracker 通过 WAL 写入 log 文件的内容是3种事件(当然,会进行序列化): - BlockAdditionEvent(receivedBlockInfo: ReceivedBlockInfo);即新增了一个 block 及该 block 的具体信息,包括 streamId、blockId、数据条数等
- BatchAllocationEvent(time: Time, allocatedBlocks: AllocatedBlocks);即为某个 batchTime 分配了哪些 blocks 作为该 batch RDD 的数据源
- BatchCleanupEvent(times: Seq[Time]);即清理了哪些 batchTime 对应的 blocks
2、WAL 在 executor 端的应用
Receiver 接收到的数据会源源不断的传递给 ReceiverSupervisor,是否启用 WAL 机制(即是否将 spark.streaming.receiver.writeAheadLog.enable 设置为 true)会影响 ReceiverSupervisor 在存储 block 时的行为:- 不启用 WAL:你设置的StorageLevel是什么,就怎么存储。比如MEMORY_ONLY只会在内存中存一份,MEMORY_AND_DISK会在内存和磁盘上各存一份等
- 启用 WAL:在StorageLevel指定的存储的基础上,写一份到 WAL 中。存储一份在 WAL 上,更不容易丢数据但性能损失也比较大
3、WAL 使用建议
关于是否要启用 WAL,要视具体的业务而定:- 若可以接受一定的数据丢失,则不需要启用 WAL,WAL开启了以后会减少Spark Streaming处理数据的吞吐,因为所有接收的数据会被写到到容错的文件系统上,这样文件系统的吞吐和网络带宽将成为瓶颈。
- 若完全不能接受数据丢失,那就需要同时启用 checkpoint 和 WAL,checkpoint 保存着执行进度(比如已生成但未完成的 jobs),WAL 中保存着 blocks 及 blocks 元数据(比如保存着未完成的 jobs 对应的 blocks 信息及 block 文件)。同时,这种情况可能要在数据源和 Streaming Application 中联合来保证 exactly once 语义
此处参考:
7、HDFS操作的一系列问题
1、ls操作
列出子目录和文件(不包括嵌套层级):listStatus(path,filter)列出所有(包括嵌套层级):listFiles(path,true)Path file = new Path(HDFSConst.live_path);FileStatus[] statuslist = hdfs.listStatus(file, (v) -> { return v.getName().contains(prefix) && !v.getName().endsWith(HDFSConst.processSubffix); });List paths = new ArrayList ();for (FileStatus status : statuslist) { Path tmp = new Path(status.getPath().toString()); RemoteIterator statusIter = hdfs.listFiles(tmp, true); boolean shouldAdd = true; while (statusIter.hasNext()) { LocatedFileStatus status2 = statusIter.next(); if (status2.getPath().toString().contains("/_temporary/")) { shouldAdd = false; break; } } if (shouldAdd) { paths.add(tmp); }} 2、hadoop No FileSystem for scheme:
问题来源:This is a typical case of the maven-assembly plugin breaking things. Different JARs (hadoop-commons for LocalFileSystem, hadoop-hdfs for DistributedFileSystem) each contain a different file called org.apache.hadoop.fs.FileSystem in their META-INFO/services directory. This file lists the canonical classnames of the filesystem implementations they want to declare (This is called a Service Provider Interface implemented via java.util.ServiceLoader, see org.apache.hadoop.FileSystem line 2622). When we use maven-assembly-plugin, it merges all our JARs into one, and all META-INFO/services/org.apache.hadoop.fs.FileSystem overwrite each-other. Only one of these files remains (the last one that was added). In this case, the FileSystem list from hadoop-commons overwrites the list from hadoop-hdfs, so DistributedFileSystem was no longer declared.How we fixed it
After loading the Hadoop configuration, but just before doing anything FileSystem-relatedhadoopConfig.set("fs.hdfs.impl", org.apache.hadoop.hdfs.DistributedFileSystem.class.getName() ); hadoopConfig.set("fs.file.impl", org.apache.hadoop.fs.LocalFileSystem.class.getName() ); 不要使用maven-assembly-plugin,使用maven shade插件:
org.apache.maven.plugins maven-shade-plugin 2.3 package shade
3、Wrong FS: hdfs… expected: file:///
Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://my-master:8020"), configuration);Path filePath = new Path( );FSDataInputStream fsDataInputStream = fs.open(filePath);BufferedReader br = new BufferedReader(new InputStreamReader(fsDataInputStream)); 此处参考:
补充:关于DAG的一些概念和零散资料
RDD DAG(有向无环图,Directed Acyclic Graph):每一个操作生成一个rdd,rdd之间连一条边,最后这些rdd和他们之间的边组成一个有向无环图,就是这个dag。不只是spark,现在很多计算引擎都是dag模型的.(有向指的是 RDD 之间的依赖关系,无环是因为 RDD 中数据是不可变的)
在Spark作业调度系统中,调度的前提是判断多个作业任务的依赖关系,这些作业任务之间可能存在因果的依赖关系,也就是说有些任务必须先获得执行,然后相关的依赖任务才能执行,但是任务之间显然不应出现任何直接或间接的循环依赖关系,所以本质上这种关系适合用DAG表示。DAGscheduler简单来说就是负责任务的逻辑调度,负责将作业拆分成不同阶段的具有依赖关系的多批任务。DAGscheduler最重要的任务之一就是计算作业和任务的依赖关系,制定调度逻辑。spark中rdd经过若干次transform操作,由于transform操作是lazy的,因此,当rdd进行action操作时,rdd间的转换关系也会被提交上去,得到rdd内部的依赖关系,进而根据依赖,划分出不同的stage。
DAG是有向无环图,一般用来描述任务之间的先后关系,spark中的DAG就是rdd内部的转换关系,这些转换关系会被转换成依赖关系,进而被划分成不同阶段,从而描绘出任务的先后顺序。有向无环图(Directed Acyclic Graph, DAG)是有向图的一种,字面意思的理解就是图中没有环。常常被用来表示事件之间的驱动依赖关系,管理任务之间的调度。
在图论中,如果一个有向图无法从任意顶点出发经过若干条边回到该点,则这个图是一个有向无环图(DAG图)。
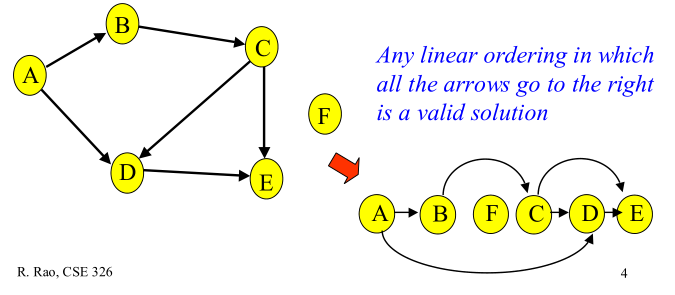
因为有向图中一个点经过两种路线到达另一个点未必形成环,因此有向无环图未必能转化成树,但任何有向树均为有向无环图。拓扑排序是对DAG的顶点进行排序,使得对每一条有向边(u, v),均有u(在排序记录中)比v先出现。亦可理解为对某点v而言,只有当v的所有源点均出现了,v才能出现。
 下图给出的顶点排序不是拓扑排序,因为顶点D的邻接点E比其先出现:
下图给出的顶点排序不是拓扑排序,因为顶点D的邻接点E比其先出现: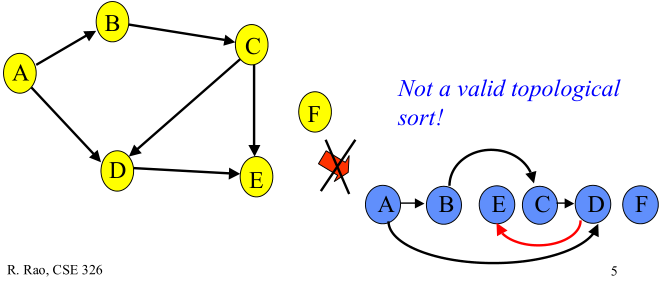
DAG可用于对数学和 计算机科学中得一些不同种类的结构进行建模。
由于受制于某些任务必须比另一些任务较早执行的限制,必须排序为一个队 列的任务集合可以由一个DAG图来呈现,其中每个顶点表示一个任务,每条边表示一种限制约束,拓扑排序算法可以用来生成一个有效的序列。DAG也可以用来模拟信息沿着一个一 致性的方向通过处理器网络的过程。DAG中得可达性关系构成了一个局 部顺序,任何有限的局部顺序可以由DAG使用可达性来呈现。Spark Streaming 的 模块 1 DAG 静态定义 要解决的问题就是如何把计算逻辑描述为一个 RDD DAG 的“模板”,在后面 Job 动态生成的时候,针对每个 batch,都将根据这个“模板”生成一个 RDD DAG 的实例。